

- cross-posted to:
- linux@lemmy.ml
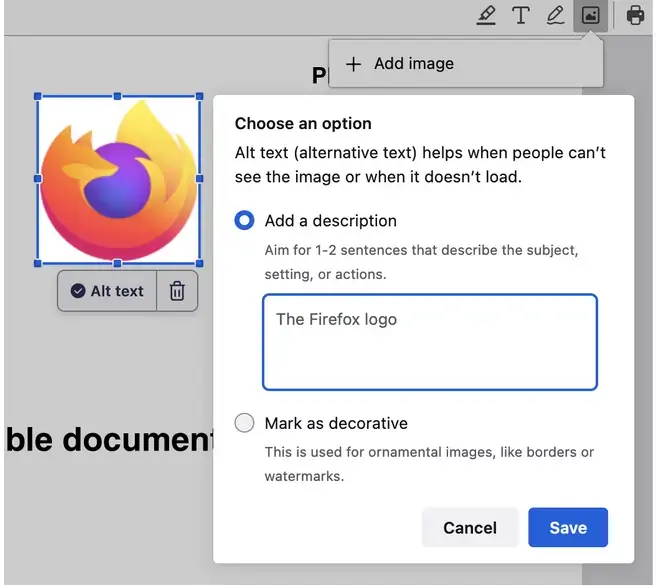
New accessibility feature coming to Firefox, an “AI powered” alt-text generator.
"Starting in Firefox 130, we will automatically generate an alt text and let the user validate it. So every time an image is added, we get an array of pixels we pass to the ML engine and a few seconds after, we get a string corresponding to a description of this image (see the code).
…
Our alt text generator is far from perfect, but we want to take an iterative approach and improve it in the open.
…
We are currently working on improving the image-to-text datasets and model with what we’ve described in this blog post…"
Now i want this standalone in a commandline binary, take an image and give me a single phrase description (gut feeling says this already exists but depending on Teh Cloudz and OpenAI, not fully local on-device for non-GPU-powered computers)
Ollama + llava-llama3
You now just need a cli wrapper interact with the ollama api
So, it’s possible to build but no one has made it yet? Because i have negative interest in messing with that kinda tech, and would rather just “apt-get install whatever-image-describing-gizmo” so i wouldn’t be the one who does it
this is how i feel about basically all technology nowadays, it’s all so artificially limited by capitalism.
nothing fucking progresses unless someone figures out a way to monetize it or an autistic furry decides to revolutionize things in a weekend because they were bored and inventing god was almost stimulating enough
Folks have made it - I think ollama was name-checked specifically because it’s on Github and in Homebrew and in some distros’ package repositories (it’s definitely in Arch’s). I think some folks (at least) aren’t talking about it because of the general hate-on folks have for LLMs these days.
I don’t want an LLM to chat with or whatever folks do with those things, i want a command i can just install, i call the binary on a terminal window with an image of some sort as a parameter, it returns a single phrase describing the image, on a typical office machine with no significant GPU and zero internet access.
Right now i cannot do this as far as i know. Pointing me at some LLM and “Go build yourself something with that” is the direct opposite of what i stated that i desire. So, it doesn’t currently seem to exist, that’s why i stated that i wished somebody ripped it off the Firefox source and made it a standalone command.
I thought that feature was built into it, but okay.
And you expect someone just do it for you? You alrady get the inferencing engine and the model for free mate.
Yes I was just writing that, I would love to see more integrations that can talk against ollama.
deleted by creator
Where is this freely available multimodal GPT4 you speak of?
deleted by creator